

Математическая статистика
![]() Регрессионный анализ
Регрессионный анализ
Линейная регрессионная модель общего вида
Пусть функция регрессии имеет вид:
|
$f(x,{{\beta }_{0}},...,{{\beta }_{k}})={{\beta }_{0}}{{\varphi }_{0}}(x)+...+{{\beta }_{k-1}}{{\varphi }_{k-1}}(x)$, |
где ${{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x)$ – некоторая система функций (не обязательно линейных).
Тогда регрессионная модель (1*) отклика Y на входное воздействие x выглядит следующим образом:
|
$Y={{\beta }_{0}}{{\varphi }_{0}}(x)+...+{{\beta }_{k-1}}{{\varphi }_{k-1}}(x)+\varepsilon (x)$. |
где $\varepsilon(x)$ – случайная ошибка модели.
Такая модель называется линейной регрессионной моделью общего вида, или просто линейной регрессионной моделью. Под линейностью регрессионной модели понимается линейность по её параметрам ${{\beta }_{0}},...,{{\beta }_{k-1}}$.
Как правило, в качестве функции ${{\varphi }_{0}}(x)$ выбирается тождественная единица:
При условии постоянства математического ожидания ошибок модели $\text{M}\left[ \varepsilon (x) \right]=const\neq 0$ такой выбор обеспечивает выполнение требования 1°, предъявляемого к регрессионным моделям.
Используя метод наименьших квадратов, найдём оценки параметров модели ${{\beta }_{0}},...,{{\beta }_{k-1}}$. Запишем систему уравнений (6*) в матричном виде:
где $\beta ={{({{\beta }_{0}},...,{{\beta }_{k-1}})}^{T}}$ – вектор параметров модели, $y={{({{y}_{1}},...,{{y}_{n}})}^{T}}$– вектор откликов модели,
|
$F=\left( \begin{matrix} {{\varphi }_{0}}({{x}_{1}}) & ... & {{\varphi }_{k-1}}({{x}_{1}}) \\ {{\varphi }_{0}}({{x}_{2}}) & ... & {{\varphi }_{k-1}}({{x}_{2}}) \\ ... & ... & ... \\ {{\varphi }_{0}}({{x}_{n}}) & ... & {{\varphi }_{k-1}}({{x}_{n}}) \\ \end{matrix} \right)$. |
Матрица F называется регрессионной матрицей, или матрицей плана (design matrix).
Решением системы (4) является вектор:
МНК-оценка функции линейной регрессии Y на X (1) в точке x имеет вид:
|
$\tilde{f}(x)=f(x,\tilde{\beta })=\sum\limits_{j=0}^{k-1}{{{{\tilde{\beta }}}_{j}}{{\varphi }_{j}}(x)}$. |
При соблюдении требований к регрессионным моделям МНК-оценки (6) и (7) имеют те же свойства, что и МНК-оценки простейшей линейной регрессионной модели, а ковариационная матрица вектора МНК-оценок $\tilde{\beta }={{\left( \tilde\beta_0,...,\tilde\beta_{k-1} \right)}^{T}}$ равна:
$\operatorname{cov}\left[ {\tilde{\beta }} \right]={{\sigma }^{2}}{{({{F}^{T}}F)}^{-1}}$,
где σ2 – дисперсия ошибок модели (2). Матрица ${{({{F}^{T}}F)}^{-1}}$ называется дисперсионной матрицей Фишера.
Доверительные интервалы на уровне значимости α для параметров ${{\beta }_{j}}$, $j=\overline{0,k-1}$, регрессионной модели рассчитываются по следующим формулам:
$\left( {{{\tilde{\beta }}}_{j}}-{{t}_{1-\alpha /2}}(n-k)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{{{c}_{jj}}} \right.;$
$\left. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {{{\tilde{\beta }}}_{j}}+{{t}_{1-\alpha /2}}(n-k)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{{{c}_{jj}}} \right),$
где cjj – j-й диагональный элемент матрицы ${{({{F}^{T}}F)}^{-1}}$, $j=\overline{0,k-1}$, ${{t}_{1-\alpha /2}}(n-k)$ – квантиль распределения Стьюдента с n–k степенями свободы на уровне 1–α/2, $\tilde{D}_{resY}^{{}}$ – несмещённая оценка остаточной дисперсии случайной величины Y:
$\tilde{D}_{resY}^{{}}=\frac{1}{n-k}\sum\limits_{i=1}^{n}{{{\left( \tilde{f}({{x}_{i}})-{{y}_{i}} \right)}^{2}}}$,
Доверительный интервал на уровне значимости α для функции регрессии $f(x)=\text{M}\left[ Y|x \right]$ в точке x имеет вид:
$\left( \tilde{f}(x)-{{t}_{1-\alpha /2}}(n-k)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{{{\varphi }^{T}}(x){{({{F}^{T}}F)}^{-1}}\varphi (x)} \right.;$
$\left. \ \ \ \ \ \ \tilde{f}(x)+{{t}_{1-\alpha /2}}(n-k)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{{{\varphi }^{T}}(x){{({{F}^{T}}F)}^{-1}}\varphi (x)}\right),$
где $\varphi (x)={{\left( {{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x) \right)}^{T}}$ – вектор значений системы функций в точке x.
Пример функции регрессии, линейной по параметрам, приведён на рисунке ниже.
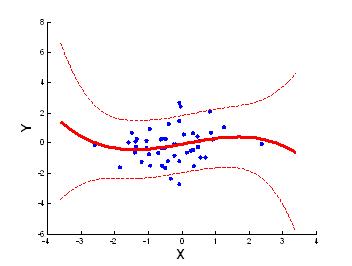
На рисунке сплошной линией изображена оцененная функция регрессии $\tilde{f}(x)={{\tilde{\beta }}_{0}}+{{\tilde{\beta }}_{1}}x+{{\tilde{\beta}}_{2}}{{x}^{2}}+{{\tilde{\beta }}_{3}}{{x}^{3}}$, пунктирными линиями – границы доверительного интервала для f(x) на уровне значимости α = 0,1.
Линейная регрессионная модель (2) называется значимой, если соответствующая ей функция регрессии зависит от x. В частности, если выполнено условие (3), то модель значима, если хотя бы один из коэффициентов ${{\beta }_{1}},...,{{\beta }_{k-1}}$ отличен от нуля. Если все ${{\beta}_{1}}=...={{\beta }_{k-1}}=0$, то модель называется незначимой.
Проверка значимости линейной регрессионной модели означает проверку гипотезы:
${{H}_{0}}:{{\beta }_{1}}=...={{\beta }_{k-1}}=0$
против альтернативной гипотезы
$H':\sum\limits_{j=1}^{k-1}{\beta _{j}^{2}}>0$.
В качестве статистики критерия используют статистику:
|
$Z=\frac{{R_{Y|X}^{2*}}/{(k-1)}\;}{{\left( 1-R_{Y|X}^{2*} \right)}/{(n-k)}\;}$, |
которая при условии истинности H0 имеет распределение Фишера с k–1 и n–k степенями свободы в числителе и в знаменателе соответственно: ${{f}_{Z}}(z|{{H}_{0}})\sim F(k-1,n-k)$.
Критическая область для статистики критерия выбирается правосторонней.
Статистика критерия (8), используемая при проверке значимости линейной регрессионной модели, представляет собой статистику (6*), используемую при проверке гипотезы о равенстве нулю коэффициента детерминации Y на X при числе неизвестных параметров функции регрессии, равном k.
Для проверки гипотезы о равенстве нулю параметра ${{\beta }_{j}}$, $j=\overline{0,k-1}$, линейной регрессионной модели:
${{H}_{0}}:{{\beta }_{j}}=0$
используют статистику критерия:
$Z=\frac{{{{\tilde{\beta }}}_{j}}}{\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{{{c}_{jj}}}}$,
которая при условии истинности H0 имеет распределение Стьюдента с n–k степенями свободы: ${{f}_{Z}}(z|{{H}_{0}})\sim T(n-k)$.
Критическая область для статистики критерия выбирается, исходя из вида альтернативной гипотезы.
Система функций ${{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x)$ может быть выбрана произвольным образом, однако на практике удобно использовать некоторую систему ортогональных функций.
Система функций ${{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x)$ называется ортогональной на множестве ${{x}_{1}},...,{{x}_{n}}$, если
|
$\sum\limits_{i=1}^{n}{{{\varphi }_{m}}({{x}_{i}}){{\varphi }_{l}}({{x}_{i}})}=0$, $\forall m,l=0,...,k-1$, $m\ne l$. |
В случае центрированных функций ${{\varphi }_{j}}(x)$, $j=\overline{0,k-1}$, т.е. функций, для которых выполнено условие:
$\sum\limits_{i=1}^{n}{{{\varphi }_{j}}({{x}_{i}})}=0$, $\forall j=0,...,k-1$,
равенство (9) в терминах математической статистики означает некоррелированность функций ${{\varphi }_{m}}(x)$ и ${{\varphi }_{l}}(x)$ при $m\ne l$:
$\operatorname{cov}\left[ {{\varphi }_{m}}(x),{{\varphi }_{l}}(x) \right]=0$, $\forall m,l=0,...,k-1$, $m\ne l$.
Можно показать, что если система функций ${{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x)$ ортогональна на множестве ${{x}_{1}},...,{{x}_{n}}$, то МНК-оценки параметров ${{\beta }_{0}},...,{{\beta }_{k-1}}$ регрессионной модели (2) вычисляются по формуле:
${{\tilde{\beta }}_{j}}=\frac{\sum\limits_{i=1}^{n}{{{y}_{i}}{{\varphi }_{j}}({{x}_{i}})}}{\sum\limits_{i=1}^{n}{\varphi _{j}^{2}({{x}_{i}})}}$, $j=\overline{0,k-1}$.
В качестве системы ортогональных функций ${{\varphi }_{0}}(x),...,{{\varphi }_{k-1}}(x)$ могут быть выбраны, например, ортогональные полиномы Чебышева или Эрмита.
|
|
|