

Математическая статистика
![]() Регрессионный анализ
Регрессионный анализ
Простейшая линейная регрессионная модель
Пусть функция регрессии Y на X имеет вид:
|
$f(x,{{\beta }_{0}},{{\beta }_{1}})={{\beta }_{0}}+{{\beta }_{1}}x$. |
Тогда регрессионная модель (1*) отклика Y выглядит следующим образом:
|
$Y={{\beta }_{0}}+{{\beta }_{1}}x+\varepsilon (x)$. |
Такая модель называется простейшей линейной регрессионной моделью (simple linear regression).
Используя метод наименьших квадратов, найдём оценки параметров модели ${{\beta }_{0}},{{\beta }_{1}}$. Запишем систему уравнений (6*):
$\begin{cases} {{\beta }_{0}}n+{{\beta }_{1}}\sum\limits_{i=1}^{n}{{{x}_{i}}}=\sum\limits_{i=1}^{n}{{{y}_{i}}}, \\ {{\beta }_{0}}\sum\limits_{i=1}^{n}{{{x}_{i}}}+{{\beta }_{1}}\sum\limits_{i=1}^{n}{x_{i}^{2}}=\sum\limits_{i=1}^{n}{{{x}_{i}}{{y}_{i}}}; \end{cases}$
решением которой являются оценки ${{\tilde{\beta }}_{0}},{{\tilde{\beta }}_{1}}$:
|
$\begin{cases} {{{\tilde{\beta }}}_{0}}=\bar{y}-\rho _{XY}^{*}\frac{\sigma _{Y}^{*}}{\sigma _{X}^{*}}\bar{x}, \\ {{{\tilde{\beta }}}_{1}}=\rho _{XY}^{*}\frac{\sigma _{Y}^{*}}{\sigma _{X}^{*}}.\end{cases}$ |
Таким образом, МНК-оценка значения простейшей линейной функции регрессии Y на X (1) в точке x имеет вид:
$\tilde{f}(x)=f(x,{{\tilde{\beta }}_{0}},{{\tilde{\beta }}_{1}})=\bar{y}+\rho _{XY}^{*}\frac{\sigma _{Y}^{*}}{\sigma _{X}^{*}}(x-\bar{x})$.
Заметим, что найденные МНК-оценки параметров простейшей линейной регрессии являются выборочными оценками теоретических значений (9*), рассчитанных для функции регрессии нормально распределённых случайных величин.
Оценки ${{\tilde{\beta }}_{0}},{{\tilde{\beta }}_{1}}$ имеют следующие свойства:
1. они являются линейными функциями результатов наблюдений ${{y}_{1}},...,{{y}_{n}}$;
2. состоятельность, т.е ${{\tilde{\beta }}_{i}}\overset{P}{\mathop{\to }}\,{{\beta }_{i}}$ при $n\to \infty $, $i=0,1$;
3. несмещённость, т.е. $\text{M}\left[ {{{\tilde{\beta }}}_{i}} \right]={{\beta }_{i}}$, $i=0,1$.
Пусть к регрессионной модели (2) наряду с требованиями 1° и 2° налагаются следующие дополнительные требования (условия Гаусса-Маркова).
3°. Неизменность дисперсии ошибок $\varepsilon(x)$ для всех x из рассматриваемой области определения:
Требование постоянства дисперсии произвольных случайных величин ${{\xi }_{1}},...,{{\xi }_{n}}$ называется требованием их гомоскедастичности. Если дисперсии случайных величин ${{\xi }_{1}},...,{{\xi }_{n}}$ различны, то такие величины называются гетероскедастичными.
Регрессионная модель называется гомоскедастичной, если гомоскедастичны её ошибки, т.е. если выполнено условие (4) для всех x из рассматриваемой области определения.
Наличие свойства гомоскедастичности ошибок простейшей линейной регрессионной модели связано с гомоскедастичностью наблюдаемой случайной величины Y при различных значениях x. Так, если при различных x дисперсии случайной величины Y различны, то регрессионная модель будет гетероскедастичной.
Иногда гетероскедастичность данных можно обнаружить визуально (например, на рисунке справа). Если диаграммы рассеяния не дают явной информации, тогда применяются статистические тесты на гомоскедастичность.
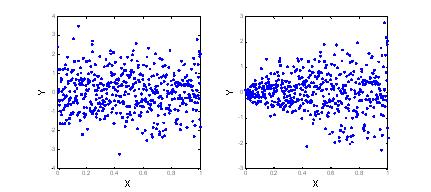
Наличие гетероскедастичности в наблюдениях случайной величины Y приводит к неэффективности оценок ${{\tilde{\beta }}_{0}},{{\tilde{\beta}}_{1}}$ и $\tilde{f}(x)$.
4°. Независимость ошибок $\varepsilon(x)$ и $\varepsilon (x')$ модели для всех x и x' из рассматриваемой области определения.
Если известно, что ошибки модели имеют нормальное распределение $\varepsilon (x)\sim{\ }N(0,{{\sigma }^{2}})$ при всех x, то требование независимости эквивалентно требованию некоррелированности:
$\operatorname{cov}\left[ \varepsilon (x),\varepsilon (x') \right]=0$.
Наличие свойства независимости остатков простейшей линейной регрессионной модели связано с независимостью наблюдаемых значений случайной величины Y при различных значениях x. Иными словами, выборка наблюдений ${{y}_{1}},...,{{y}_{n}}$ должна быть реализацией независимой случайной выборки ${{Y}_{1}},...,{{Y}_{n}}$. Если это требование не выполняется, то МНК-оценки ${{\tilde{\beta }}_{0}},{{\tilde{\beta }}_{1}}$и $\tilde{f}(x)$ являются неэффективными (теорема Гаусса-Маркова).
Свойства 3° и 4° эквивалентны выполнению условия
$V_\varepsilon={{\sigma }^{2}}I$,
где Vε – ковариационная матрица ошибок регрессионной модели, I – единичная матрица.
При соблюдении требований 1°–4° оценки ${{\tilde{\beta }}_{0}},{{\tilde{\beta }}_{1}}$ и $\tilde{f}(x)$являются эффективными, т.е. оценками с наименьшей дисперсией в классе всех линейных несмещённых оценок. Эти дисперсии равны:
$D\left[ {{{\tilde{\beta }}}_{0}} \right]=\frac{{{\sigma }^{2}}\sum\limits_{i=1}^{n}{x_{i}^{2}}}{nD_{X}^{*}},$
$D\left[ {{{\tilde{\beta }}}_{1}} \right]=\frac{{{\sigma }^{2}}}{nD_{X}^{*}}.$
Доверительные интервалы на уровне значимости α для параметров ${{\beta }_{0}},{{\beta }_{1}}$ регрессионной модели рассчитываются по следующим формулам:
|
$\left( {{{\tilde{\beta }}}_{0}}-{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{\sum\limits_{i=1}^{n}{x_{i}^{2}}}{{{n}^{2}}D_{X}^{*}}}\right.;$ $\left. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {{{\tilde{\beta }}}_{0}}+{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{\sum\limits_{i=1}^{n}{x_{i}^{2}}}{{{n}^{2}}D_{X}^{*}}} \right),$ |
|
$\left( {{{\tilde{\beta }}}_{1}}-{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{1}{nD_{X}^{*}}} \right.;$ $\left. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {{{\tilde{\beta }}}_{1}}+{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{1}{nD_{X}^{*}}}\right),$ |
где ${{t}_{1-\alpha /2}}(n-2)$ – квантиль распределения Стьюдента с n–2 степенями свободы на уровне 1–α/2, $D_{X}^{*}$ – выборочная дисперсия случайной величины X, $\tilde{D}_{resY}^{{}}$ – несмещённая оценка остаточной дисперсии случайной величины Y:
$\tilde{D}_{resY}^{{}}=\frac{1}{n-2}\sum\limits_{i=1}^{n}{{{\left( \tilde{f}({{x}_{i}})-{{y}_{i}} \right)}^{2}}}$,
Доверительный интервал на уровне значимости α для функции регрессии $f(x)=\text{M}\left[ Y|x \right]$ в точке x имеет вид:
$\left( \tilde{f}(x)-{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{1}{n}+\frac{{{(x-\bar{x})}^{2}}}{nD_{X}^{*}}} \right.;$
$\left. \ \ \ \ \ \ \ \ \ \ \ \ \ \tilde{f}(x)+{{t}_{1-\alpha /2}}(n-2)\sqrt{\tilde{D}_{resY}^{{}}}\sqrt{\frac{1}{n}+\frac{{{(x-\bar{x})}^{2}}}{nD_{X}^{*}}} \right).$
Отметим, что границы доверительного интервала для функции регрессии f(x) нелинейно зависят от x.
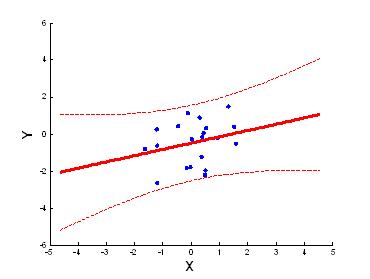
На рисунке сплошной линией изображена оцененная функция регрессии $\tilde{f}(x)$, пунктирными линиями – границы доверительного интервала для f(x) на уровне значимости α = 0,1.
Простейшая регрессионная модель (2) называется значимой, если ${{\beta }_{1}}\ne 0$.
Для проверки значимости простейшей регрессионной модели сформулируем основную и альтернативную гипотезы:
${{H}_{0}}:{{\beta }_{1}}=0,$
$H':{{\beta }_{1}}\ne 0.$
В качестве статистики критерия используется статистика:
|
$Z=\frac{R_{Y|X}^{2*}}{{\left( 1-R_{Y|X}^{2*} \right)}/{(n-2)}\;}$, |
которая при условии истинности H0 имеет распределение Фишера с 1 и n–2 степенями свободы в числителе и знаменателе соответственно: ${{f}_{Z}}(z|{{H}_{0}})\sim{\ }F(1,n-2)$.
Критическая область для статистики критерия выбирается правосторонней.
Заметим, что статистика критерия (7), используемая при проверке значимости простейшей линейной регрессионной модели, представляет собой статистику (6*), используемую при проверке гипотезы о равенстве нулю коэффициента детерминации Y на X при числе неизвестных параметров функции регрессии k = 2. Фактически проверка гипотезы о значимости регрессионной модели – это проверка гипотезы о равенстве нулю коэффициента детерминации при функции регрессии (1).
|
|
|